How to Avoid Creating Duplicate Accounts During eTapestry Imports
If you need to add or update large quantities of data in a short amount of time, eTapestry imports are usually the way to go.
Imports can save you significant time and effort on data entry by allowing you to add or modify data in batch. As a result, the risk of error is much greater. You want to cautiously approach each new import because there is no undo button for an import gone wrong.
If you’re feeling overwhelmed or intimidated by eTapestry imports, start by identifying the steps you can take to maintain data quality and data health.
While there are many ways to ensure success with eTapestry imports (more on that here), minimizing duplicate accounts is often a top priority.
How can you minimize duplicate accounts during an import?
1. Use the correct import file
Your eTapestry database has built-in safeguards to prevent importing the same data file more than once with the same import template, but there are some scenarios where it is possible.
For example, if you run recurring imports of the same type or are running multiple imports at the same time (say if you split your import file due to the 2,000 row limit), it is possible to accidentally select a data file from a prior import run. If you changed the structure of the prior import file after it was imported, by sorting rows, removing/adding rows, or formatting columns, the eTapestry import tool may allow you to run the import a second time without recognizing it as the same file.
While importing a duplicate file is rare, good file management is an essential practice for eTapestry imports.
Use clear names for each eTapestry import file, including:
- Description of the data
- Date of the export from the source system or the import date
- File version (like “final”) if the data has been altered since export from the source system
- Sequence of the data if you split an original source file with more than 2,000 rows into multiple smaller files
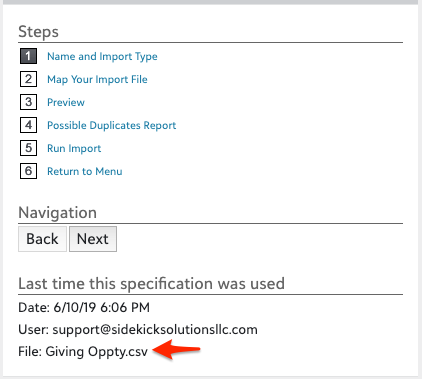
Before import, you can also check the file name listed under “Last time this specification was used” to confirm that you aren’t choosing a duplicate data file for import.
2. Remove duplicates from your import file
The eTapestry import tool runs a duplicate check on data that already exists in your eTapestry database, but will not identify duplicate rows associated with new accounts within the same import file. A new account is one that isn’t in your eTapestry database yet. Depending on the type of import (account or journal entry), you may need to confirm that your import file doesn’t include multiple rows per new account.
If you’re importing accounts…
Review your spreadsheet carefully for accounts with the same name or contact information. Consolidate or remove duplicate data from your import file. We recommend using Excel’s conditional formatting rules or remove duplicates feature to assist in quick identification and removal of duplicate accounts.
If you’re importing journal entries…
Confirm that each row is a unique journal entry. If your file includes multiple rows (journal entries) for the same account and some accounts are not in eTapestry, import a file of accounts first before importing journal entries. Also confirm that the account data for each journal entry associated with a single account is the same. The potential duplicate check fields of your import like name and contact information must be the same across all rows of the same account for eTapestry to match a duplicate on import.
3. Select a solid duplicate check (key)
The best duplicate check values for import are:
- Account Number
- Account Name and Email
- Account Name and Address Lines
Account number is a perfect duplicate match if it is available for import. Using account number as your import key offers nearly no chance of creating duplicates in eTapestry.
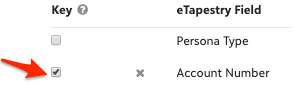
Account number isn’t always available as a duplicate check. If account number is not available, choose two other fields for your duplicate match (key). While Account Name and a piece of contact information like Email or Address are great, not every import will use these exact combinations. Select duplicate check fields that offer a complete data set where there is likely to be a unique match, but not too stringent that a potential match might be overlooked because there isn’t enough matching data in eTapestry.
4. Split your import file and use different duplicate check values
The eTapestry import tool allows for only one key or combination of keys as a duplicate check for a single import. This can be a problem if your import file contains incomplete or partial data across the desired duplicate check fields.
For example, what duplicate check should you use if half of the data in your import file has an email listed and another half has an address listed?
Selecting email over address or address over email could result in duplicate accounts for the rows of data in your file that are missing a value for the duplicate key field.
Avoid creating duplicate accounts from incomplete data in your file by splitting your import file into multiple files: one for each duplicate check key or combination of keys.
Then, import each file with a corresponding import template that uses the Account Name and the duplicate check value (like email or address) you’ve isolated in your file as the keys. Separate imports for each duplicate check increases your chances of matching to existing accounts in your eTapestry database.
5. Skip unmatched duplicates and re-import with a different duplicate check
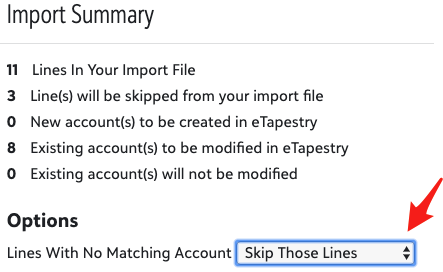
Another way to reduce duplicates is to run your import and skip the lines in your file that don’t match with existing accounts. After your import is complete, eTapestry will provide you an “Exclusion Report” of these skipped lines that you can then manually review, adding more data if needed, and identifying a more appropriate duplicate check for the skipped accounts.
You can skip lines in your file when you reach Step 4: Possible Duplicates Report, by selecting “Skip Those Lines” in the Import Summary Options for Lines With No matching Account.
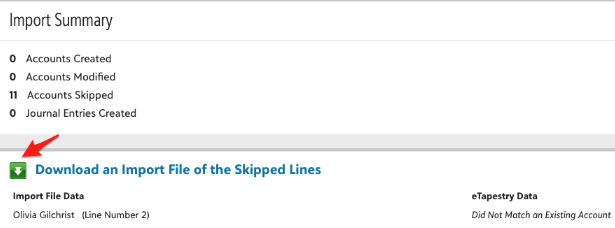
This will exclude all rows where the account didn’t match and provide you an exclusion report after you run the import. Repeat your import with the excluded accounts and pick a different duplicate check value as your key.
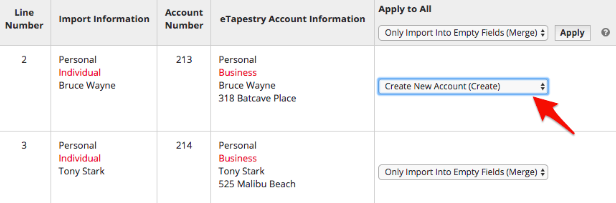
6. Review possible duplicates before import
When running your import, carefully review duplicate statistics on Step 4: Possible Duplicates Report. When deciding how to handle each potential duplicate, only select “Create New Account” for accounts in your report if you’re certain they are not duplicates and you’ve completed Tip #4 above.
Duplicates are inevitable, so always run the Duplicate Report post import
Even with all of the pre-import steps above, your import may still create duplicate accounts. There are no surefire ways to ensure a duplicate-free import (unless you match on Account Number). We recommend running the Duplicate Report after each import.
Running the Duplicate Report serves as an audit of your import and closes the loop on data quality. Even if you run the Duplicate Report each month, it’s still best practice to run an off-schedule duplicate check immediately following an import. This is especially important if you’re importing a large quantity of data.
Follow these steps to run the Duplicate Report and merge or ignore duplicates:
- Select Reports
- Select eTapestry Standard Reports
- Select Duplicate Report from the Account Reports category
- Select a Category of Base
- Select a Query of All Constituents – A
- Select Schedule for Off Hours and schedule the report to run overnight
- When the report has run, access the report in eTapestry by completing steps 1-3 above and selecting View Existing Report
- Follow the onscreen instructions to merge or ignore each duplicate pair

Minimizing duplicate accounts during an import is an active process that involves multiple strategies and tactics. With a measured approach to each new import and the application of best practices to your process, you can ensure data health and quality while still benefiting from the efficiency of eTapestry imports.
Do you run recurring imports from other apps?
If you run recurring imports to and from eTapestry, MailChimp, Eventbrite, QuickBooks Online, Shopify, WooCommerce, PayPal, or any other app, contact us to learn about automated integrations for eTapestry. We can set up custom automations between eTapestry and your other apps that remove the need to manually import data to eTapestry.
Free Download
The Essential Kit to eTapestry Best Practices
- 4x PDF Guides
- 1x Template/Worksheet
- 1x 60-minute Webinar
- Here we can add a benefit, or we can delete one.
Join the 700+ users that already got their kit!
DOWNLOAD NOW